Debian
All code releases at Brandscreen are packaged as deb packages and a number of reference files are also packaged as deb packages. Configuration is nearly all done through puppet. Any cron jobs simply call a wrapper.A number of third party applications, including pip packages, were packaged as debs.
The deb packages are all installed in a repository. The dependencies made it easy to upgrade and downgrade packages. Therefore we could release very frequently with the confidence that if there were any problems the software and configuration could be rolled back easily.
Puppet
Puppet is used for all configuration that is not handled by a debian. Also most tasks are performed using puppet. Very little is performed using ssh.
Graphing and Monitoring
Brandscreen uses Teamcity to build and deploy releases. We generally deployed to a canary first, then checked the graphs in Graphite and Gdash. If there were any issues the release would then be rolled back.Some of the items which were graphed in GDash are:
- discrepancy with partner
- CPU usage
- disk throughput
- disk space used
- network throughput
- memory usage
- partner bid requests
- partner bid responses
- partner impressions
- clicks
- number of log files
- pricing
- response times
- spending
- offline requests
- many many many other things that would give away proprietary information :)
I really can't understate how cool GDash is. And graphite itself is er useful. Here is an example from the GDash website: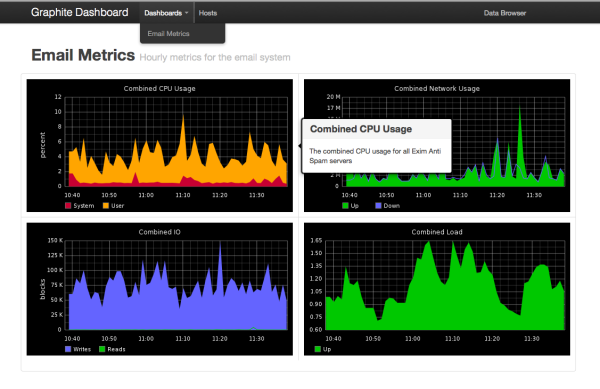
Many other items including custom logging is available through graphite itself. The data was collected through collectd.
Nagios and pagerduty are used for monitoring. To present the graphs for big screens newrelic and geckoboard are used.
I will go into more detail on graphing and alerts in a later article.
Teamcity
Teamcity is used to build, package and test each check-in. In addition deployment is done through teamcity.